
Does Machine Learning and Artificial Intelligence have a practical application to the WordPress community? That is the question that the University of Sydney have been exploring for me over the last several months. I am delighted and astonished by the results!
Hype vs Reality
Artificial Intelligence (AI) is the label for technology that can simulate human intelligence. Machine Learning (ML) is a subfield where knowledge is automatically extracted from the data.
These terms are currently being thrown around so much that I have found it difficult to distinguish between hype and reality. Upon deeper research I discovered an undercurrent of opinion that these technologies required large data sets and hence are only appropriate for use in large enterprise applications.
So not relevant to the average WordPress developer then?
When in doubt, experiment!
Most websites contain forms that collect data. Many are simply contact forms, and there is also a broad range of other uses including surveys, assessments, registrations, sales and more.
Website owners can be curious about insights hidden within their data, but typically lack the time or capability to expose them. My hypothesis is that an automated analysis tool connected to their form data has value.
Website forms may have hundreds or thousands of entries, but usually not the hundreds of thousands or more that are recommended for AI or ML application.
I tasked a team from the University of Sydney to investigate “Machine Learning on small datasets for commercial application”. Their challenge was to test a dataset collected via a WordPress Gravity Form containing only 1,200 entries.
Undaunted by traditional thinking, Antony, Altankhuyag, Dian, Fatimah and Maria, accepted the challenge.
What can we see in customer support tickets?
I asked the team to find out what insights Machine Learning could spot within GFChart support tickets. For privacy reasons these were first de-identified and had confidential data removed.
Support can be a significant expense for many businesses. Effective management can be constrained by a limited oversight of the ticket content. The opportunity to see the big picture, automatically, is therefore significant.
Training the algorithms
Successful application of Machine Learning relies upon the algorithm being trained. A variety of methods were trialled which can be classified as:
- Supervised
- Semi-supervised
- Unsupervised
As their titles suggest, these relate to the amount of human supervision required.
Tickets were successfully categorised
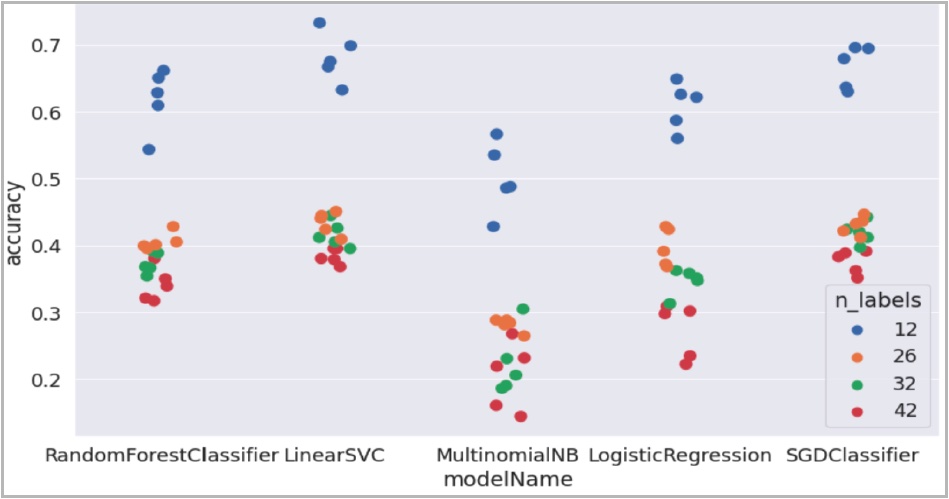
Tickets were categorised into support issue groups. For Supervised and Semi-supervised the number of groups trialled were 12, 26, 42 and 42. For Unsupervised 3 groups were trialled.
The accuracy of grouping was generally highest for the supervised training method using the fewest number of categories.
The highest accuracy achieved was 74% using the Linear Support Vector Classifier into 12 groups.
Was anything unsuccessful?
To be frank, I wasn’t expecting the project to be successful due to the size of the dataset used. Against a surprisingly successful backdrop, there was one trial that did not work.
We trialled sentiment analysis on the tickets to see whether the algorithm could automatically detect the level of frustration in the support they were receiving.
This was unsuccessful because the vast majority of the ticket content was factual rather than emotional. I believe this is because we only analysed the first ticket received from the customer, not the entire conversation thread.
What does this mean?
While we need to be careful about making big promises on the basis of 1 project, it does appear that:
- Machine Learning can be successfully used with the sort of modest dataset sizes often encountered within WordPress applications.
- Ideal for categorisation according to text based content.
- Suitable for applications that do not require 100% accuracy.
- There is a trade off between accuracy and investment in algorithm training supervision.
In summary, for the right application there is opportunity to use Machine Learning in WordPress. Ultimately it of course comes down to product market fit!
I owe massive thanks to the University of Sydney team who delivered this project to such a high standard – Antony, Altankhuyag, Dian, Fatimah, Maria and supervisor Tin.
What next?
I am very keen to hear from customers who have a need for an automated categorisation solution and would be happy to discuss their needs with me.
Potential use cases I imagine include:
- Support tickets
- Sales enquiries
- Feedback surveys
- Assessment reports
I would also love to hear from developers with Machine Learning and Natural Language Processing experience keen to get their teeth into a new project.
I invite you to contact me via GFChart support!